Monitoring Device Health and Performance at Scale with FlowFuse
Track and Optimize Edge Device Performance with Node-RED and FlowFuse.
Edge devices are everywhere, and their numbers are skyrocketing—from 2.7 billion in 2020 to a projected 7.8 billion by 2030, according to various reports. As these devices become critical for automation and data processing, monitoring their health is essential to ensure reliability and efficiency.
Tracking CPU usage, memory, and system performance helps detect potential issues early, preventing downtime and optimizing operations. In this post, we will explore how to monitor devices using Node-RED and scale this process efficiently with FlowFuse.
What is Device Health Monitoring, and Why is it Important?
Edge devices power IoT and automation, handling communication and data processing. As their numbers grow, ensuring they run efficiently is crucial.
Monitoring device health means tracking key metrics like CPU usage, memory, uptime, and system load. High CPU usage or low memory can slow down processes, disrupt data flow, and reduce efficiency.
For example, in manufacturing, edge devices connect machines to cloud systems for real-time data. If a device fails, production can be impacted.
Regular monitoring helps detect issues early, prevents downtime, and keeps devices running smoothly.
Getting Started with Monitoring Devices
We will begin by monitoring a single device, such as a Raspberry Pi, collecting system data, and visualizing it using FlowFuse. Once the process is clear, we will expand it to monitor multiple devices at scale.
Prerequisites
Before you begin, ensure you have the following:
- Running Node-RED Instance: You need a running Node-RED instance on the device you want to monitor. The easiest way to set this up is with the FlowFuse Device Agent, which provides secure remote access, real-time collaboration, snapshots for quick recovery, DevOps tools, and device group management. With it, you can push updates to multiple devices with a single click.
For a step-by-step installation guide, refer to the FlowFuse Device Agent Quickstart.
If you haven’t yet signed up for a FlowFuse account, sign up now.
- Required Node-RED Nodes: To collect system data and display it on a dashboard, install the following Node-RED nodes via the Node-RED Palette Manager:
node-red-contrib-os: Retrieves system information such as memory, uptime, and load.node-red-contrib-cpu: Monitors CPU usage.@flowfuse/node-red-dashboard: Provides UI components for visualizing system metrics.node-red-contrib-moment: Formats uptime duration in a human-readable format.
Collecting CPU and System Metrics with Node-RED
Now that Node-RED is running on your device, it’s time to gather essential system metrics. Monitoring CPU usage, memory consumption, system uptime, and load averages helps you monitormonitor performance and spot potential issues before they become serious problems.
Let’s break it down step by step.
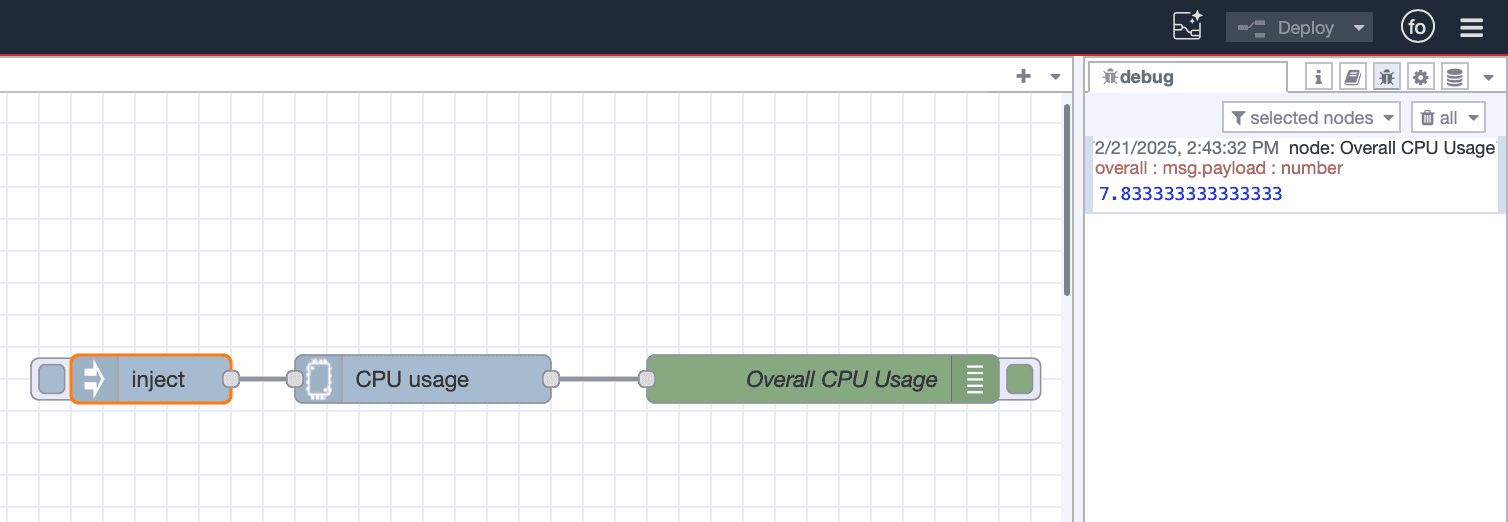
Collecting CPU Usage Data
To start, let’s capture CPU usage in real time:
- Drag a CPU node from the "Performance" category onto the canvas.
- Double-click the node and uncheck all options except "Send a message for overall usage." This ensures you get a clear view of total CPU performance. If you need per-core metrics, you can enable the other options.
- Add an Inject node, double-click it, and set it to trigger at a suitable interval (e.g., every second, every 10 seconds, or every 30 seconds). Connect its output to the CPU node.
- Add a Debug node and connect it to the output of the CPU node. This lets you view CPU data in the debug pane.
- Click Deploy in the top-right corner of the Node-RED editor.
Your debug pane will now start showing live CPU usage data:
Monitoring Memory Usage
Next, let’s track memory consumption:
- Drag a Memory node onto the canvas and double-click it.
- Choose the unit for memory display (e.g., gigabytes for easier readability).
- Connect the Memory node’s input to the Inject node’s output.
- Connect the Memory node’s output to the existing Debug node.
- Click Deploy to start monitoring.
Once deployed, you will see a structured object in the debug pane containing along with cpu usage:
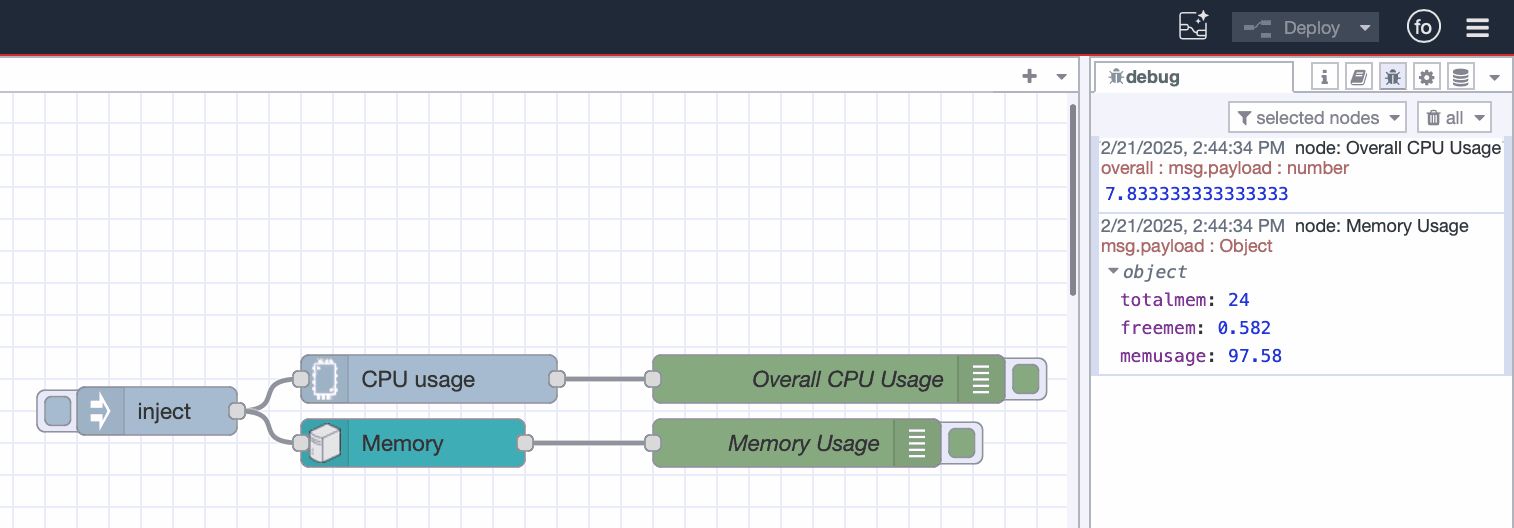
- totalmem: Total available memory
- freemem: Free memory
- memusage: Current memory usage
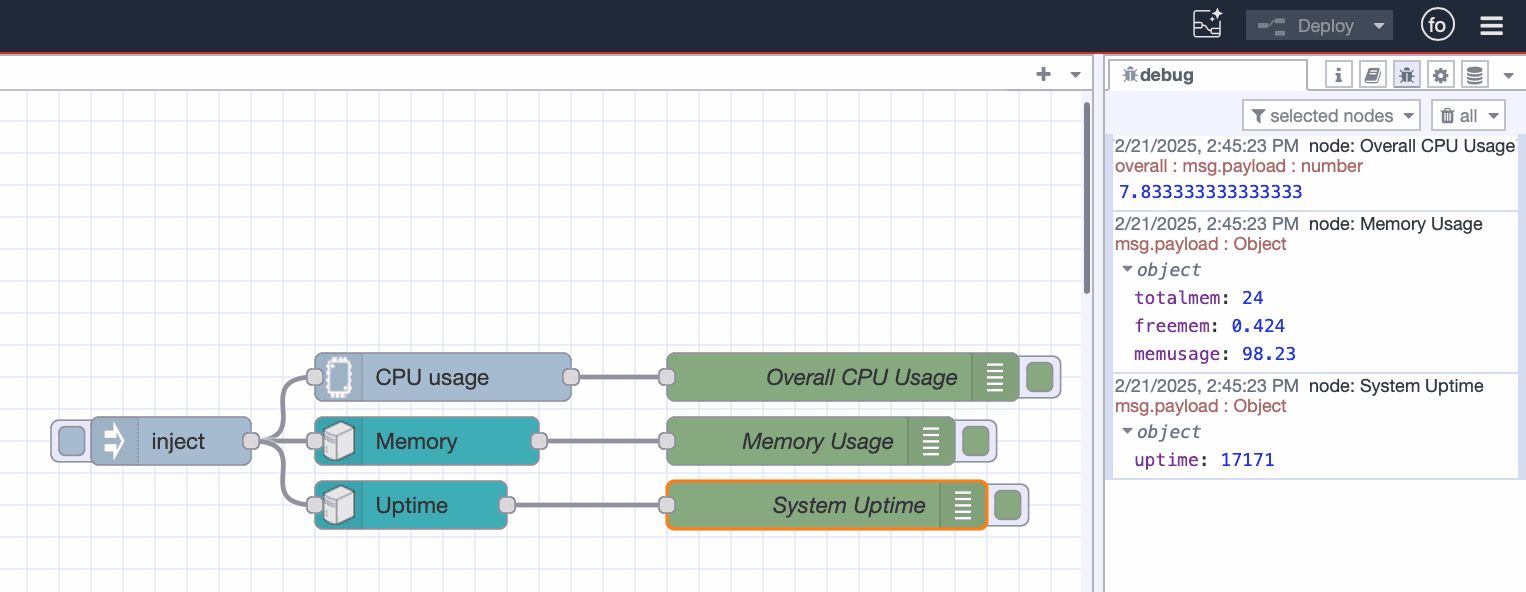
Tracking System Uptime
Monitoring uptime helps detect unexpected reboots and ensures system stability.
- Drag an Uptime node onto the canvas.
- Connect its input to the Inject node’s output.
- Connect its output to the Debug node.
- Click Deploy to activate uptime tracking.
Each time the Inject node triggers, the debug pane will display the uptime in seconds and CPU and memory usage.
Analyzing Load Average
To understand how busy your system has been over time, let’s analyze the load average:
- Drag a Loadavg node onto the canvas.
- Connect its input to the Inject node’s output.
- Connect its output to the Debug node.
- Click Deploy to start tracking.
This will give you three key metrics:
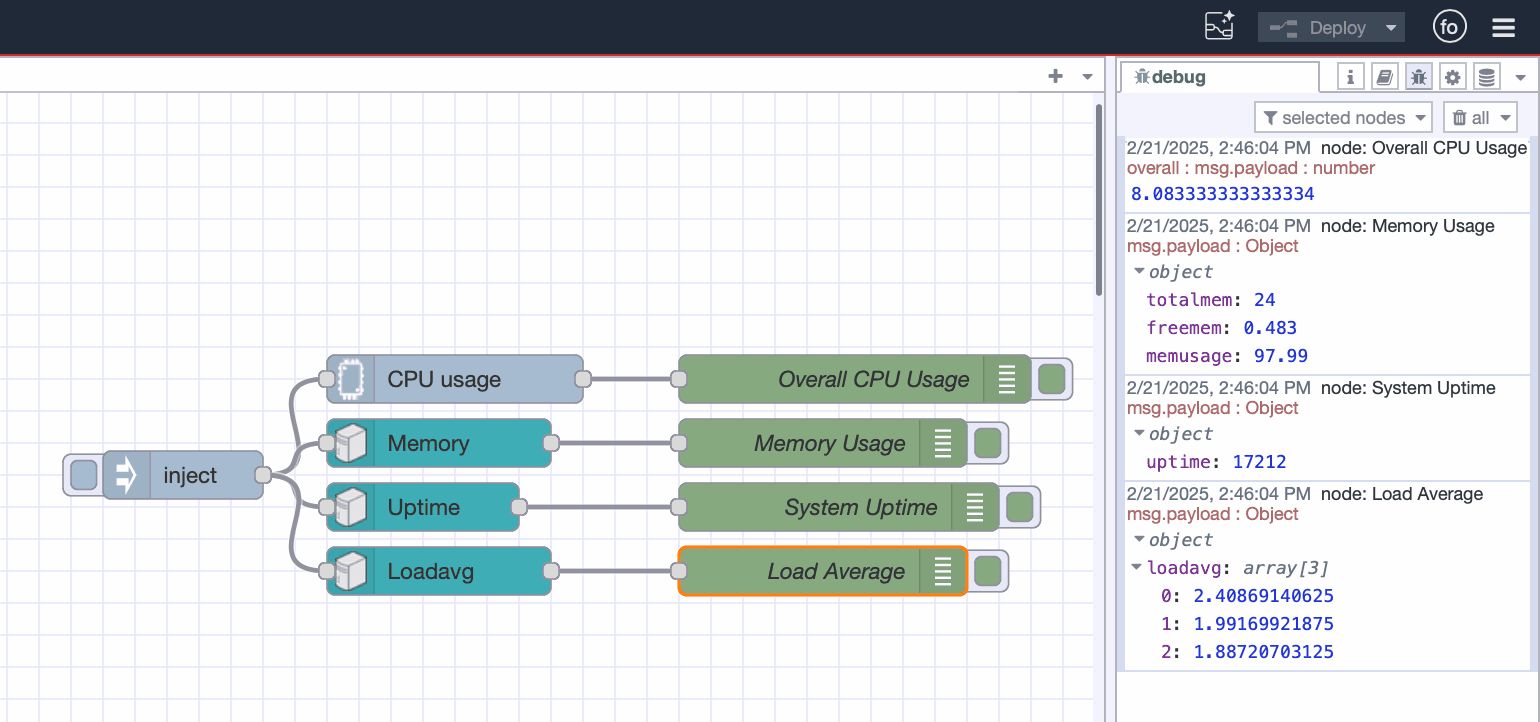
- 1-minute load average: Immediate system load
- 5-minute load average: Recent short-term trend
- 15-minute load average: Long-term system trend
If these values remain consistently high, your system may struggle under excessive demand, signaling a need for optimization or additional processing power.
With these metrics in place, you have a solid foundation for real-time system monitoring.
Sharing Data Across Different Node-RED Instances
Once we have the data, we must send it to the Node-RED instance handling visualization. Keeping the dashboard separate is essential for scalability. As the number of devices increases, a dedicated instance ensures we can monitor all of them from a single, centralized dashboard. This approach also makes management more efficient.
To send data between multiple Node-RED instances we can use FlowFuse's Project Nodes.
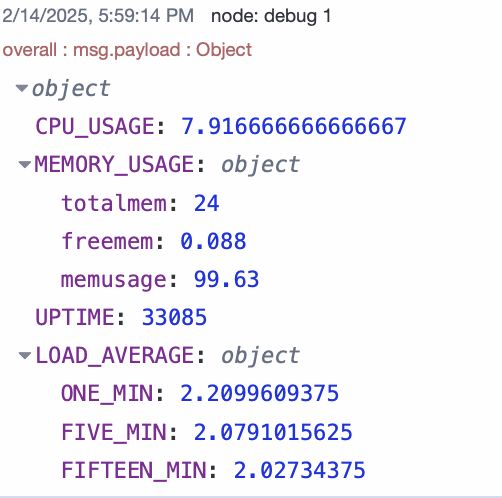
Before sending the data though, we combine all collected metrics into a single object for better organization and easier processing. Currently, each node sends its metrics as a separate message object. Merging them into a single object streamlines data handling and reduces message overhead.
Import the following flow and deploy it in the device instance. While I am not covering the step-by-step process here, the explanation below covers what the flow includes and how it works.
Let's understand the flow.
In the flow above, four Change nodes are used, each connected to the output of the CPU, Memory, Uptime, and Loadavg nodes. As mentioned earlier, these nodes provide their data separately as msg.payload. We use Change nodes to modify the message structure before sending the data to ensure a more structured and organized format.
Next, a Join node merges the msg.data objects from all Change nodes into a single data object. After that, another Change node assigns this combined object to msg.payload.
The final combined object appears as shown in the image below:
To share this data with other Node-RED instances, we use the Project Out node, which is available exclusively on FlowFuse. It works similarly to the Node-RED Link nodes, but allows for communication between multiple Instances, and uses MQTT in the background, so also beenfits with topic hierarchies for any communications.
In this Project node, we broadcast the message across all instances in the team using ${FF_DEVICE_NAME} as the topic—an environment variable automatically created in all FlowFuse instances.
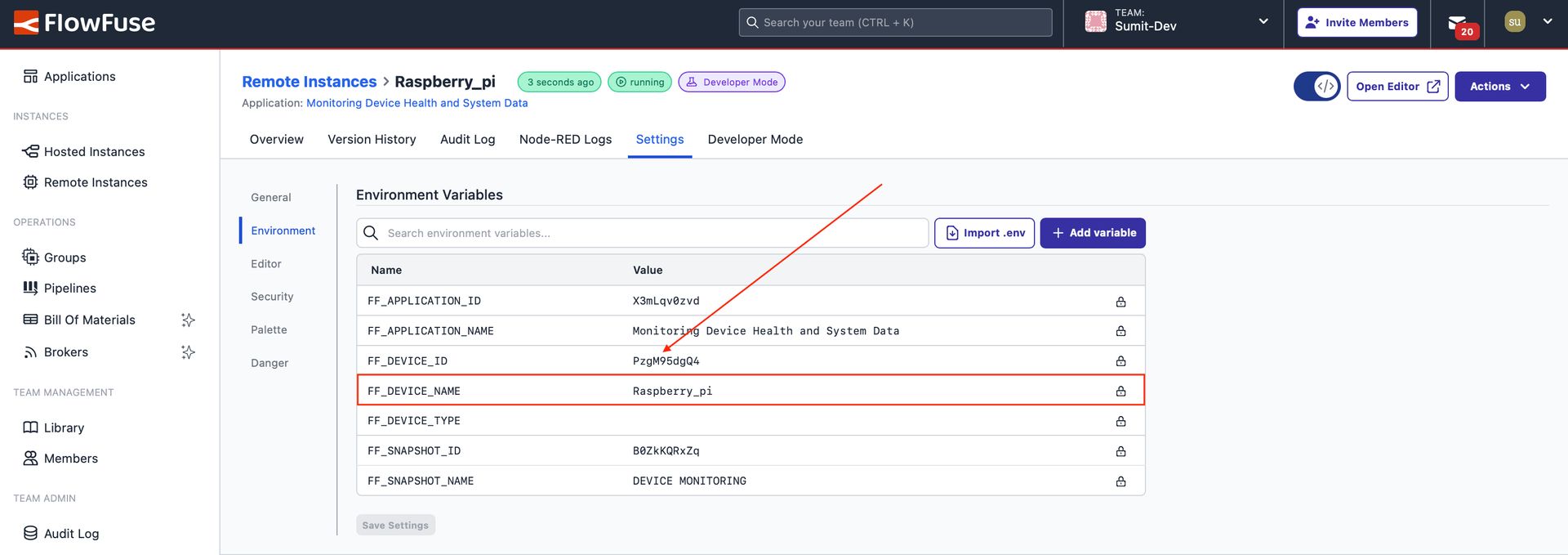
Using environment variables as the topic enables the same flow to be used across multiple devices without modification, ensuring that each device utilizes its own environment variables (device name) and sends data under its respective topic.
Visualizing Data with the FlowFuse Dashboard
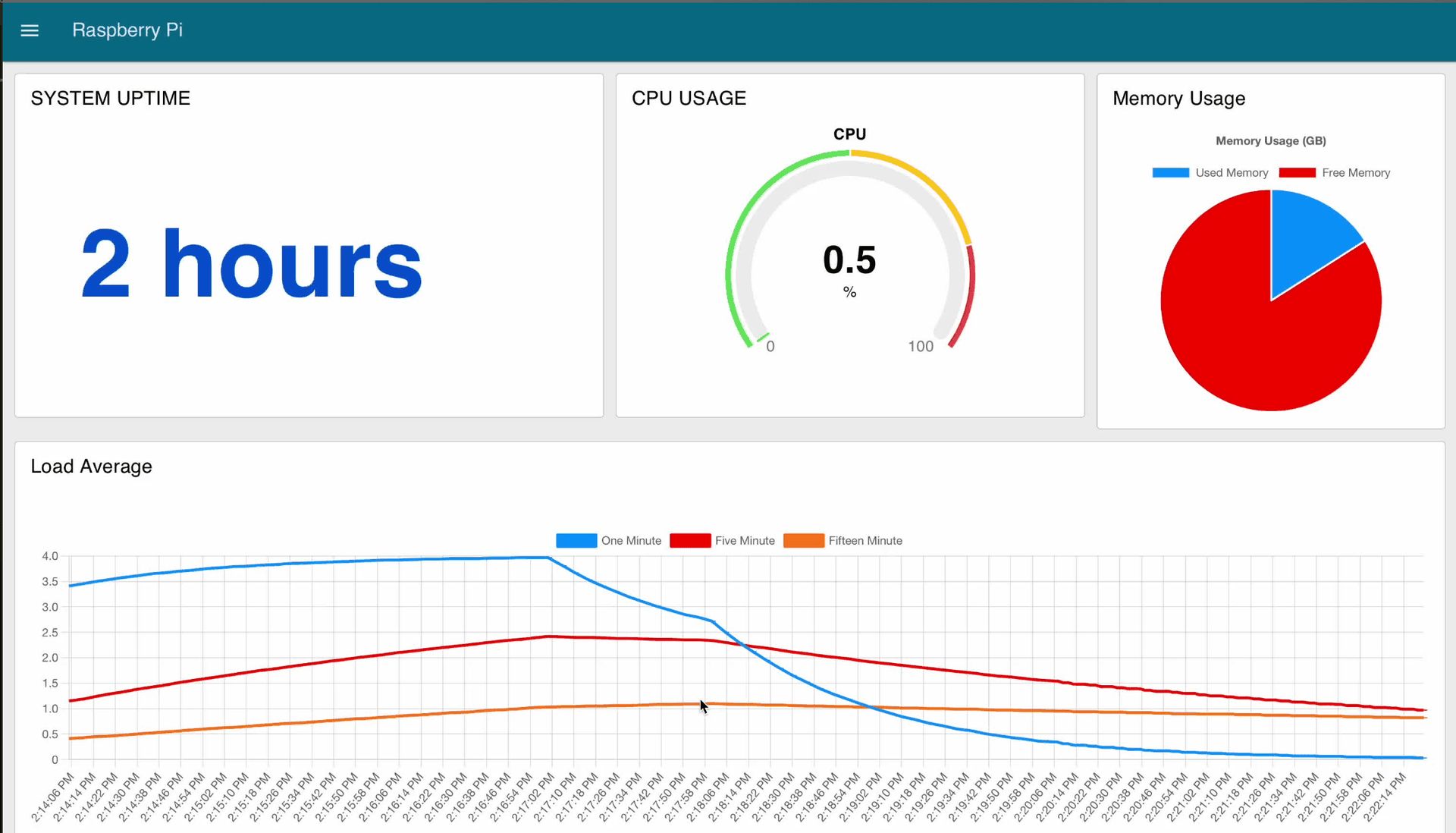
Now that the data is being broadcasted, it can be used to build a simple dashboard that visualizes it with different types of charts.
Ensure that a separate Hosted Instance has been created in the same Team where the hardware is registered. This instance will be used to deploy the dashboard.
Setting Up the Data Source
- Drag the Project In node onto the canvas.
- Double-click on it and select "Listen for broadcast messages from".
- Choose "All instances and devices" from the "Source" dropdown menu.
- Enter the device name in the topic field, ensuring it matches exactly with the
${FF_DEVICE_NAME}device environment variable. - Click Done.
Memory Usage Visualization
- Drag two Change nodes onto the canvas.
- Double-click on the first Change node. Set
msg.payloadto:payload.MEMORY_USAGE.totalmem - payload.MEMORY_USAGE.freemem - Set
msg.topicto "USED MEMORY" and click Done. - Double-click on the second Change node, Set
msg.payloadto:msg.payload.MEMORY_USAGE.freemem - Set
msg.topicto "Free Memory" and click Done. - Drag a ui-chart widget onto the canvas.
- Double-click on the widget and create a new Group.
- Set the chart type to "Pie" and action to "Append".
- Set X to
msg.topicand leave Y empty. - Click Done.
- Connect the nodes as follows:
Project In node → Change nodes → ui-chart widget
CPU Usage Visualization
- Drag a Change node onto the canvas.
- Double-click on the node. Set
msg.payloadto:$round(payload.CPU_USAGE, 2) - Click Done.
- Drag a ui-gauge widget onto the canvas.
- Double-click on the widget and create a new group.
- Set the height and size.
- Select "3/4 gauge" with a rounded style.
- Set the range from 0 to 100.
- Add three segments with colors: 0 (Green), 50 (Yellow), 80 (Red).
- Set the label to "CPU" and unit to %.
- Click Done.
- Connect the nodes as follows:
Project In node → Change node → ui-gauge widget
System Uptime Visualization
- Drag the Humanizer node onto the canvas.
- Double-click on the node and enter "UPTIME" in the input variable field.
- Click Done.
- Drag a Change node onto the canvas.
- Double-click on the node. Set
msg.payloadto:msg.payload.humanized - Click Done.
- Drag a ui-text widget onto the canvas.
- Double-click on it and create a new group.
- Select the correct layout.
- Check the "Apply Styles" option and select the color, font, and size that best suits your needs.
- Click Done.
- Connect the nodes as follows:
Project In node → Humanizer node → Change node → ui-text widget
Below is the complete dashboard flow, which visualizes the system data we collected.
Scaling Device Monitoring with FlowFuse
Now that we have learned how to monitor a single device, built a flow to gather system data, and created a dashboard to visualize those metrics, the real challenge arises when scaling up to thousands or even tens of thousands of devices. Manually creating a system data-gathering flow for each device would be impractical. However, FlowFuse can automate this process in less than five minutes. Let's see how.
Creating Device Group
- Navigate to the FlowFuse platform and go to the Application where your devices are and where you want to create a group. Ensure that all the devices you want to monitor are part of this application.
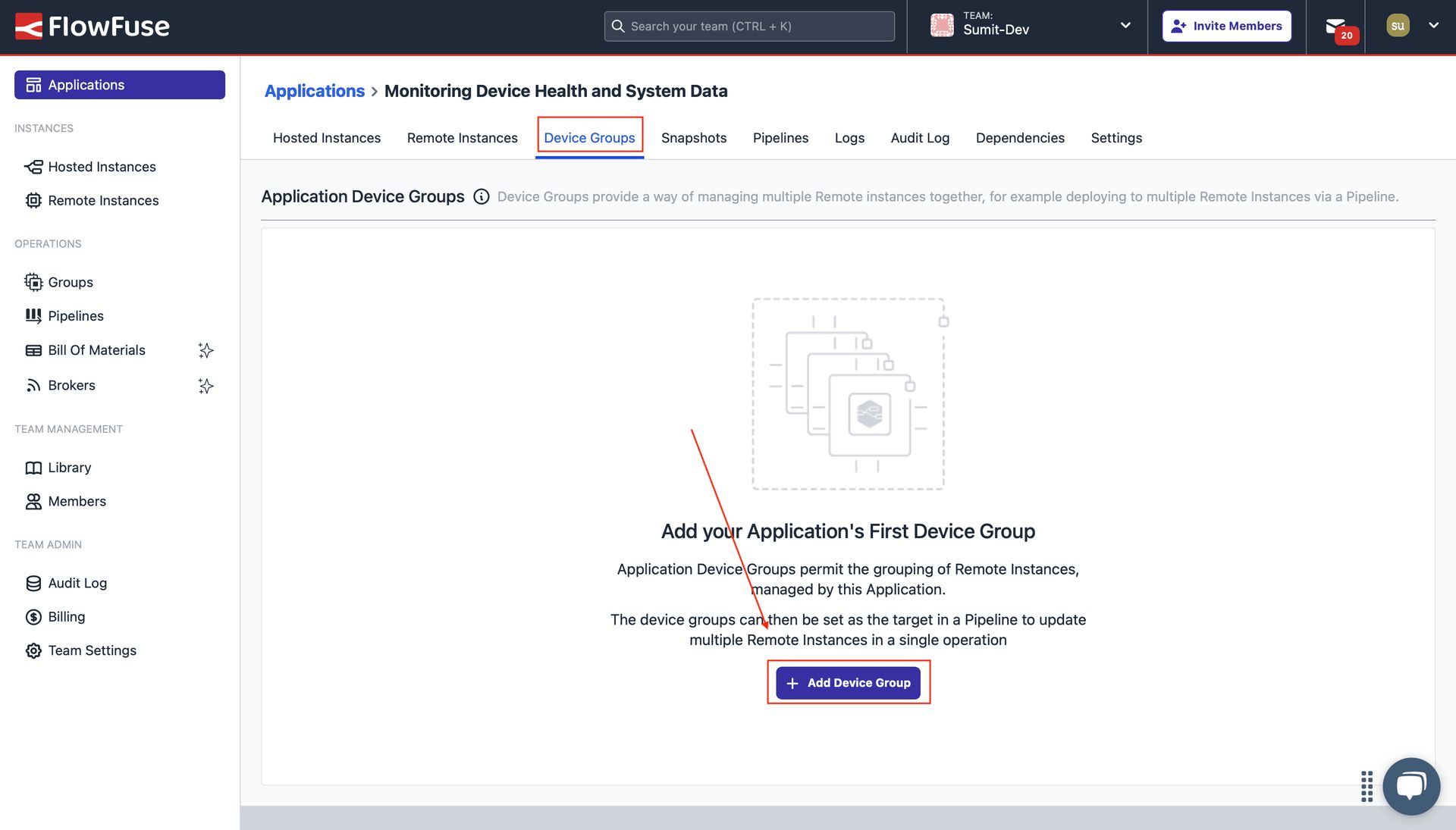
Showing the option to switch to "Device Groups" and the "Add Device Group" button.
- Click on "Device Groups" from the top menu. Next, click on the "Add Device Group" button. In the newly opened window, enter a group name and description, then click "Create".
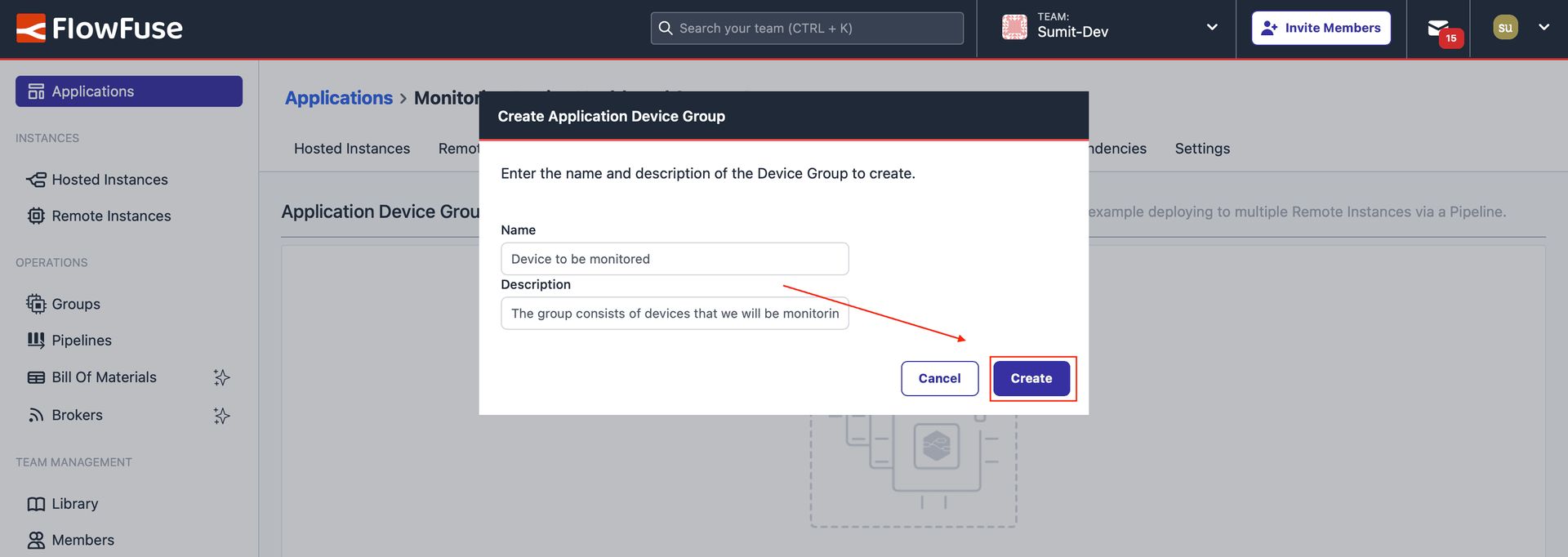
Form to Create a Device Group: Enter the group name and description
- Click on the newly created group and then click the "Edit" button at the top-right.
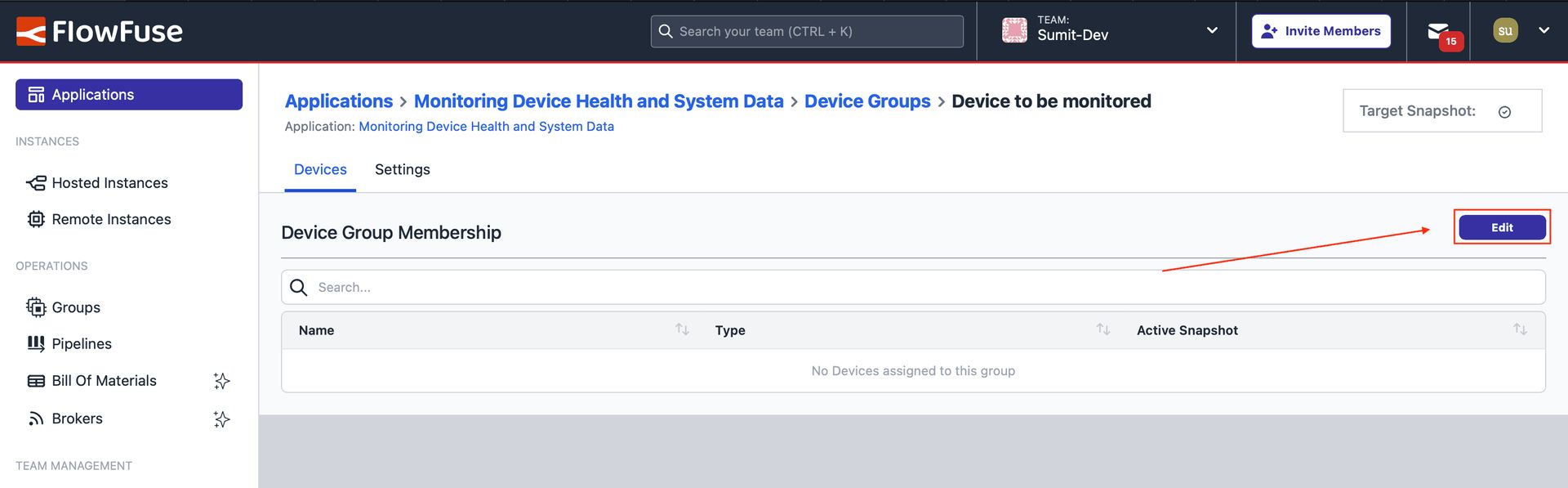
Image showing the edit button to be clicked on.
- Next, in the left-side container, you will see a list of all available devices in your application. Select the devices you want to add to the group (make sure to add only the devices that require the deployment of the flow built to gather system metrics). Click the "Add Devices" button at the top-right of that container, and then click "Save Changes". Once done, you will see all added devices in the right-side container, confirming that they have been successfully added to the group.
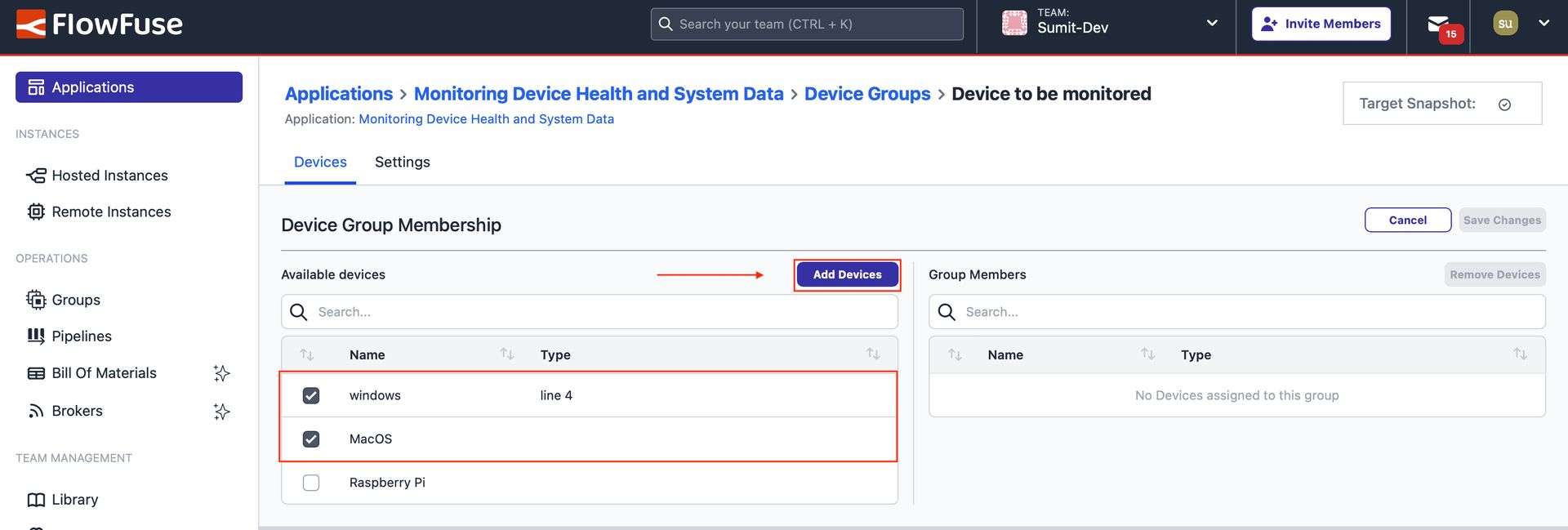
Interface to select the devices that must be added to the group, along with the 'Add Devices' button.
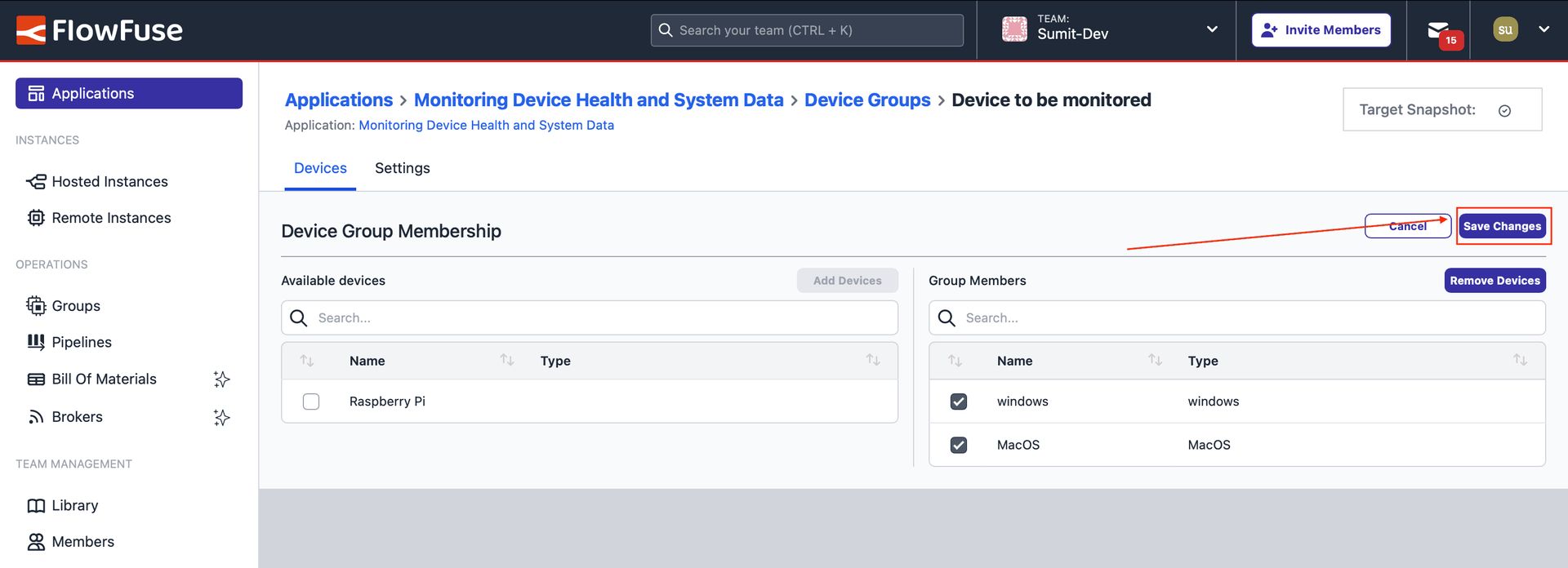
Showing the selected devices we chose to add, along with the 'Save Changes' button.
Creating Snapshot
-
Navigate to the Remote Instance on which we developed the flow to monitor performance. Switch to "Version History" by clicking on "Version History" from the top.
-
Go to the Snapshots tab and create a new snapshot by clicking the "Create Snapshot" button. Enter details such as the name and description. While making the snapshot, ensure the "Set as Target" option is checked before clicking "Create". Enabling this option sets the created snapshot as the device’s active snapshot. Later, this snapshot will be used for deployment on devices within the device group via the DevOps pipeline.
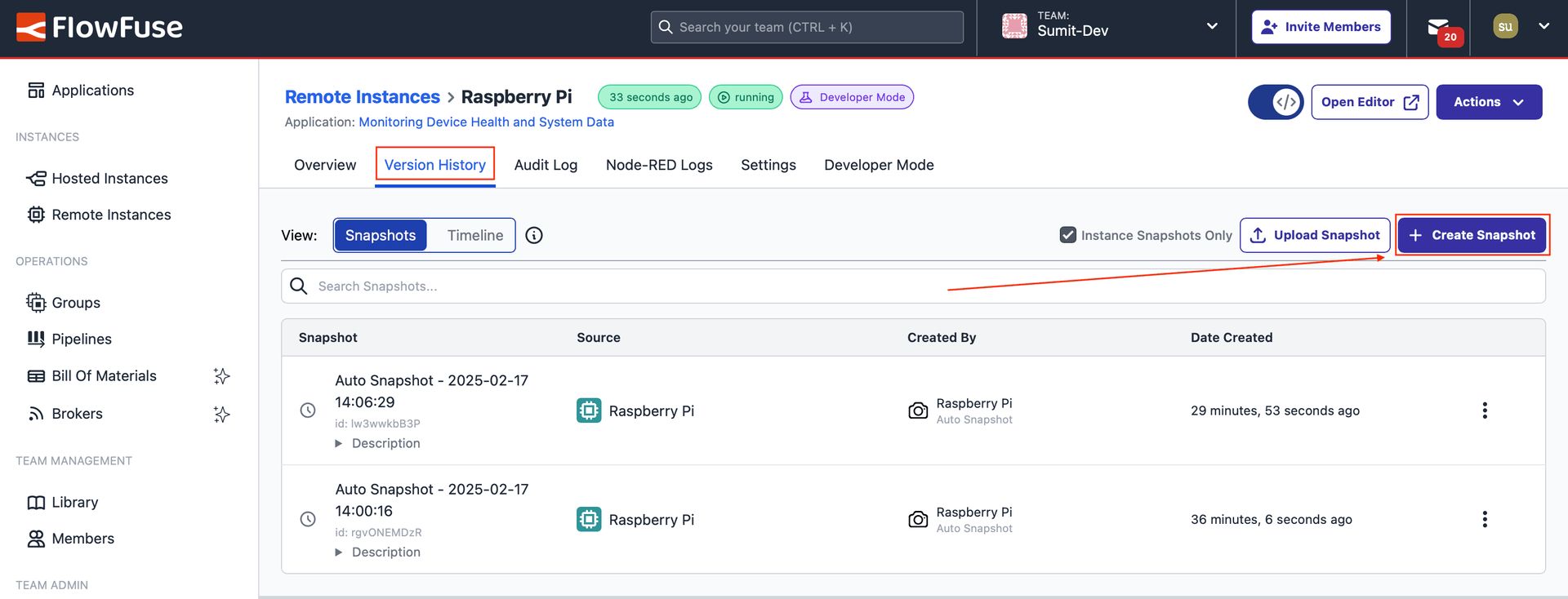
Showing the option to switch to "Version history" and the "Create Snapshot" button.
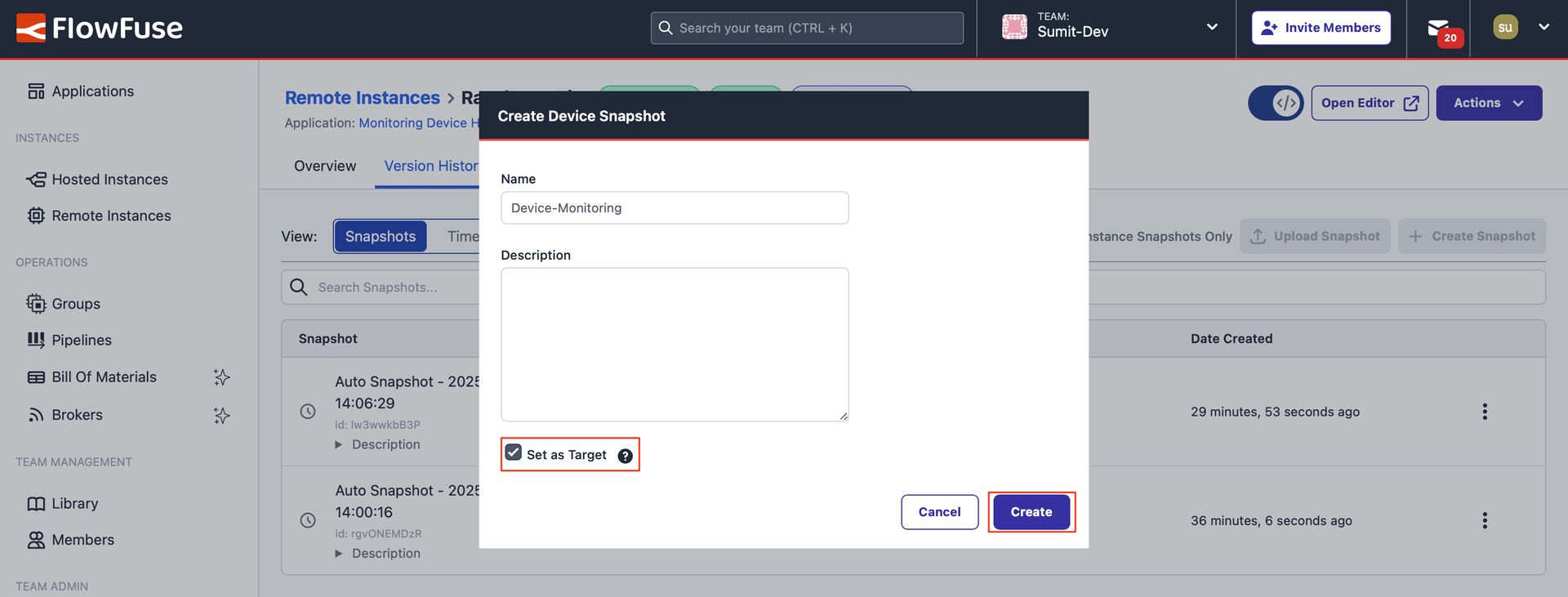
Showing the form to create a snapshot and the "Set as Target" option.
If you want to learn more about snapshots, you can read our article Using Snapshots for Version Control in Node-RED with FlowFuse.
Creating a DevOps Pipeline
- Navigate to the application where the devices were added and the device group was created. Switch to the "Pipelines" tab at the top, then click "Add Pipeline". In the newly opened window, enter a pipeline name.
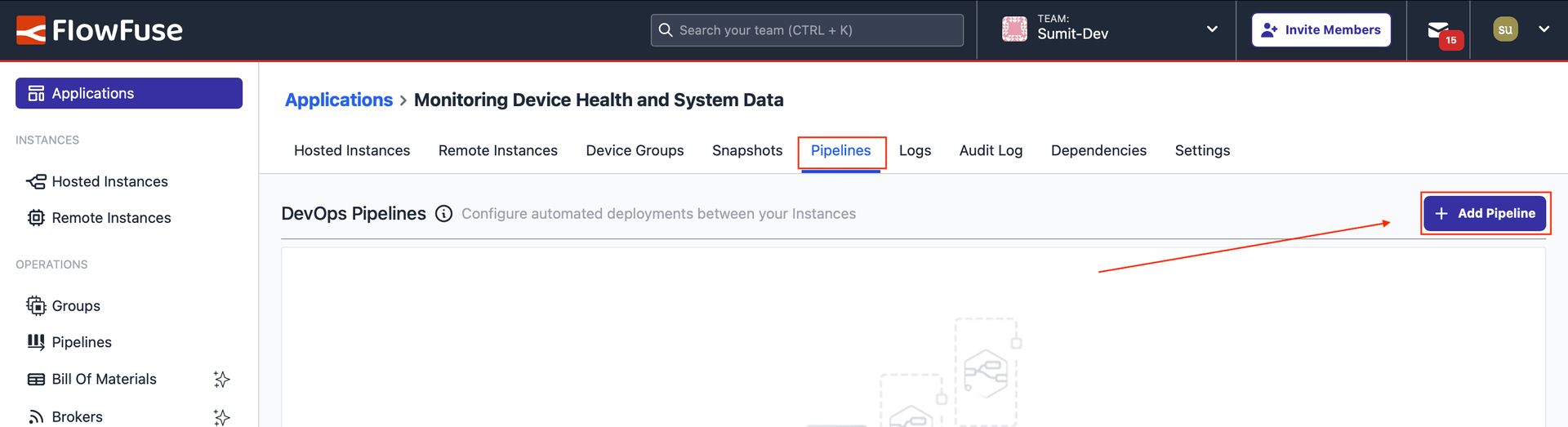
Image showing the 'Add Pipeline' button.
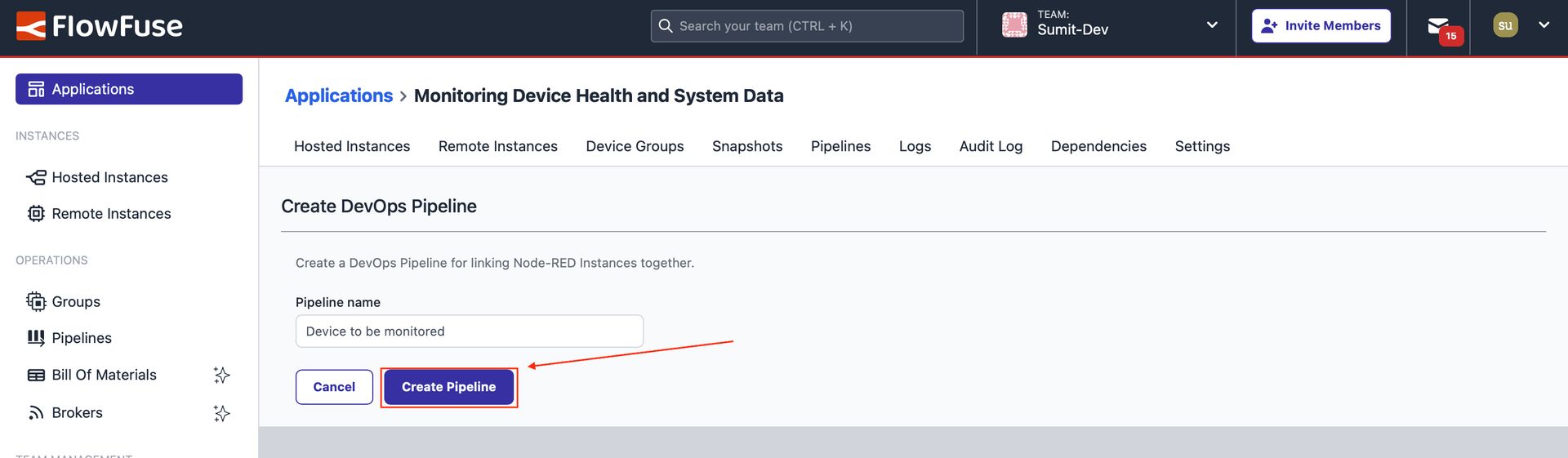
Image showing the form to create a pipeline by entering a name.
- In the newly added pipeline, click "Add Stage".
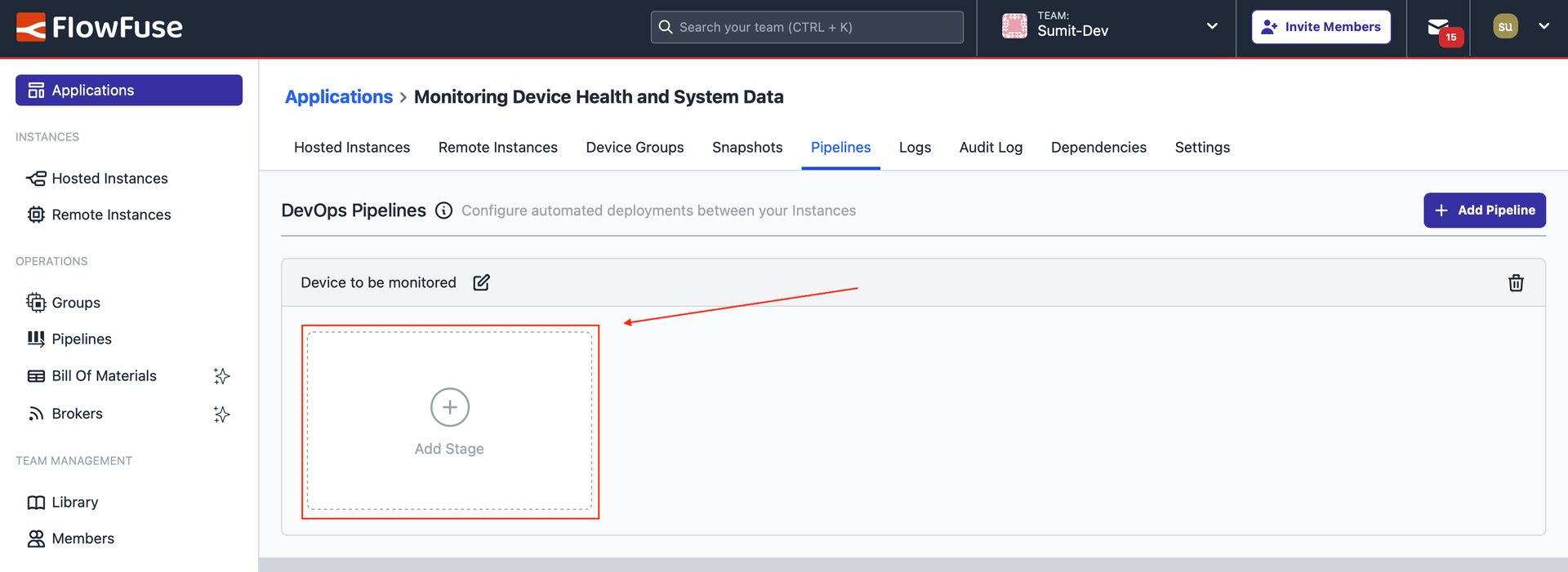
Image showing the button to add a stage.
- In the newly opened window, select "Remote Instance" as the stage type, enter a stage name, and select the device where the flow was previously built for a single device. Under "Action," select "Use active snapshot" and click "Add Stage".
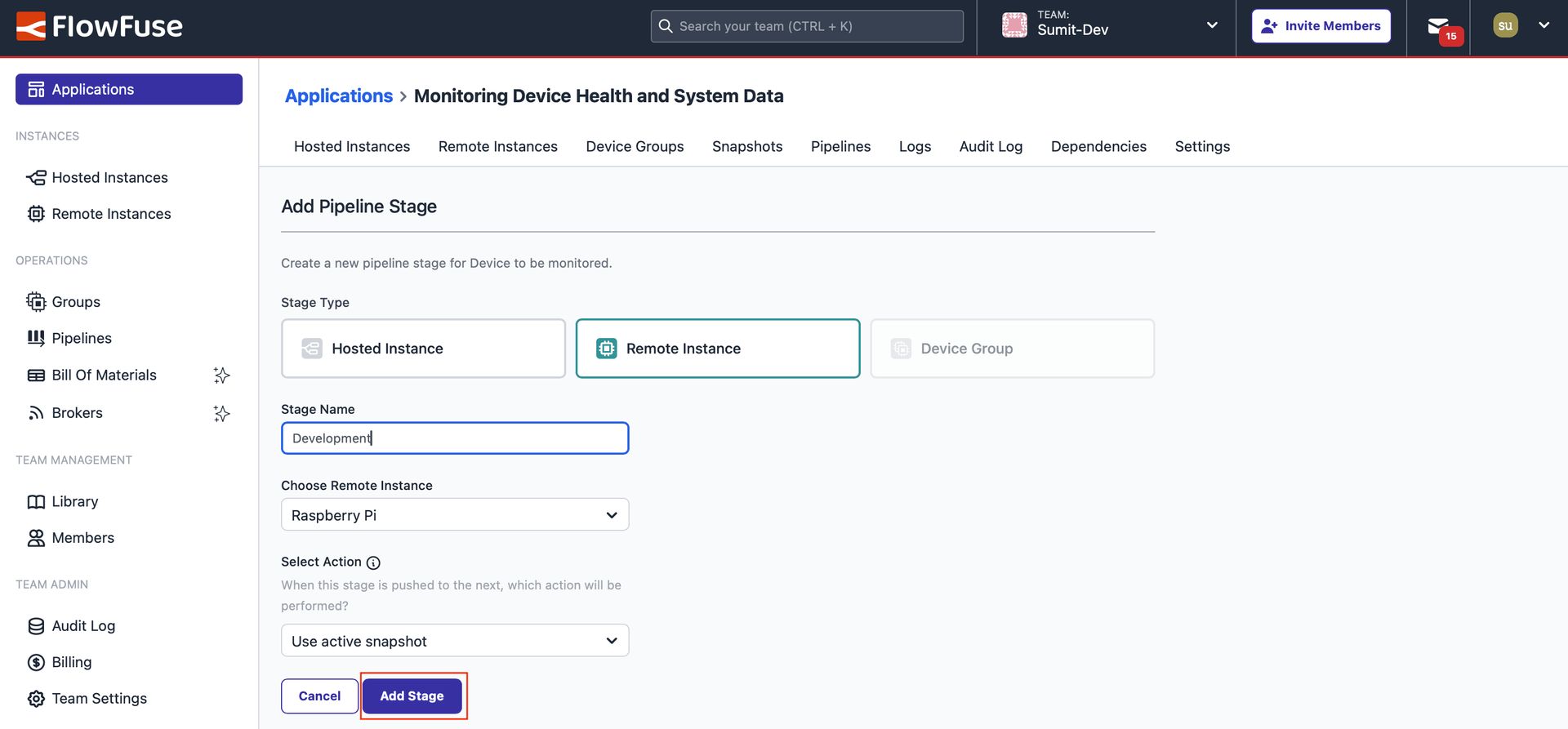
Image showing the form to add a stage, where a stage is being added for a Raspberry Pi remote instance.
- To add another stage, select "Device Group" as the stage type, enter a stage name, choose the previously created device group, and click "Add Stage."
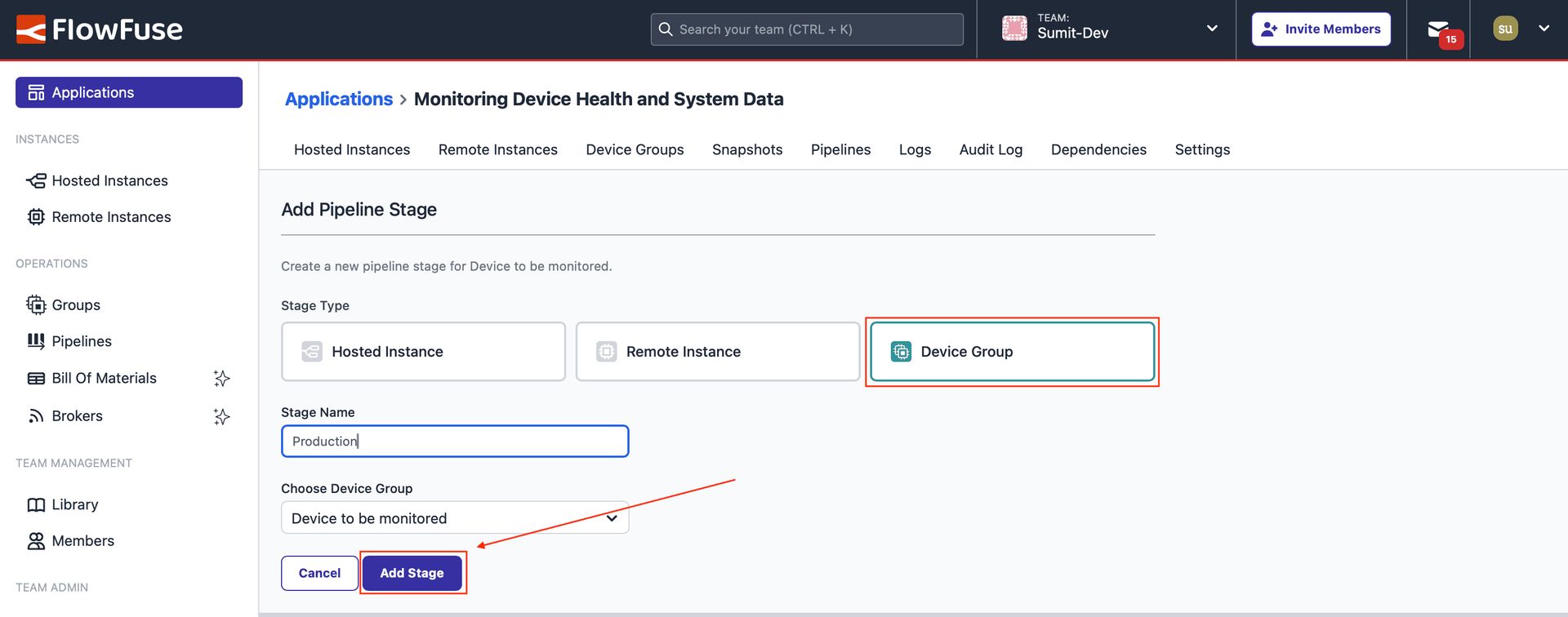
Image showing the form to add a stage, where a stage is being added for a Device Group.
- Before moving further, ensure all devices are in fleet mode.

Image showing the fleet mode status of the device (disabling the developer mode option will set the device to fleet mode).
- Once both stages are added, click the 'Run Pipeline' button for the first stage. Running the pipeline will deploy the active snapshot to the devices in the device group, including all settings, environment variables, and flows of that instance. Whether the device group has two devices or thousands, the deployment will be completed efficiently and quickly.
To learn more about DevOps pipelines, read the article: Creating and Automating DevOps Pipelines for Node-RED in Industrial Environments.
Now, you have the system data of all devices broadcasted on the topic and the device name. To monitor each device, go to the dashboard instance, copy the flow, and create copies for each device. Ensure that you replace the topic with the corresponding device name. Additionally, create a separate page for each device, assign them to separate groups, and correctly move all copied widgets into the appropriate groups. Alternatively, follow these steps again for each device, and you will have a centralized dashboard monitoring thousands of devices live.
Conclusion
Building a monitoring flow in Node-RED is simple. It allows you to track key system metrics like CPU usage, memory, and uptime with minimal effort. Its low-code Interface makes it easy to create and deploy monitoring solutions quickly.
However, manually deploying this monitoring flow across 10,000 or even 100,000 devices can be a complex and time-consuming task. This is where FlowFuse makes a difference. With features like Device Groups and DevOps pipelines, you can deploy your application from a single device or hosted Node-RED instance to thousands of devices with just a single click. FlowFuse also provides powerful tools for scaling, managing, and monitoring industrial operations, making large-scale deployments more efficient and hassle-free.
Discuss your use case with our team
See how FlowFuse can support your architecture, integrations, and deployment needs.
About the Author
Sumit Shinde
Technical Writer
Sumit is a Technical Writer at FlowFuse who helps engineers adopt Node-RED for industrial automation projects. He has authored over 100 articles covering industrial protocols (OPC UA, MQTT, Modbus), Unified Namespace architectures, and practical manufacturing solutions. Through his writing, he makes complex industrial concepts accessible, helping teams connect legacy equipment, build real-time dashboards, and implement Industry 4.0 strategies.
Table of Contents
Related Articles:
- FlowFuse + LLM + MCP = Text Driven Operations
- The Industrial IoT Market Shift: What the PTC Divestment Means for Your Data Strategy
- MCP and Custom AI Models on FlowFuse!
- EtherNet/IP Integration with FlowFuse: Communicating with Allen-Bradley PLCs
- The Node-RED Revolution: How Low-Code is Democratizing Industrial Automation