How to Scrape Data from Websites Using Node-RED
A step-by-step guide to leveraging Node-RED for efficient web scraping and automated data extraction.

Web scraping has become an indispensable tool for monitoring news, tracking competitors, and gathering insights. In this guide, you'll learn how to harness the power of Node-RED for efficient web scraping, allowing you to extract and manage data from various websites with ease that are not exposed through an API.
What is Web Scraping?
Web scraping is a technique for automatically extracting data from websites. Instead of manually copying information from web pages, web scraping uses tools or scripts to access and retrieve data from the Internet efficiently. This process allows you to quickly gather large volumes of information, which is helpful for tasks such as tracking market trends, aggregating news, or collecting product details. By automating data collection, web scraping helps save time and reduce human error. It enables users to extract and analyze structured data from various sources, making it easier to compile and utilize information for research, business intelligence, or other purposes.
Web scraping can be helpful when APIs are unavailable or do not meet your requirements. It allows you to collect data directly from web pages, which can be beneficial for tasks like competitive analysis, market research, or tracking specific online content.
How Does Web Scraping Works?
Web scraping involves systematically extracting data from websites using automated tools or scripts. The process begins with requesting a specific webpage. The response from the server is the HTML content of the page. This HTML code contains the structured information displayed on the webpage, organized in a format that describes the layout and content.
Once the HTML is received, the next step is parsing it. Parsing involves analyzing the HTML structure to identify and extract the data of interest. This may include navigating through nested elements, locating specific tags, and using selectors to target precise content such as text blocks, images, or links. The extracted data is then processed and stored in a format that suits the user's needs, whether a database, a CSV file, or another format suitable for analysis.
Web scrapping with Node-RED
In this section, we will guide you through the process of scraping data from publicly available websites using Node-RED and demonstrate how to extract data from a website specifically designed for scraping practice. For this example, we will scrape country data from the page at https://www.scrapethissite.com/pages/simple/.
Sending Requests to a Webpage
To start scraping data, follow these steps to send an HTTP GET request to the webpage:
- Drag the inject node onto the canvas. This node allows you to manually trigger the HTTP request or set it to fire at specific intervals.
- Drag the http request node onto the canvas. Double-click it to configure and set the Method to
GET.Enter the webpage URL you want to scrape (e.g.,https://www.scrapethissite.com/pages/simple/). - Drag the debug node onto the canvas.
- Connect the inject node's output to the input of the http request node and the http request node's output to the input of the debug node.
- Click Deploy to save and deploy your flow.
Once deployed, click the inject button. You will see the raw HTML printed in the debug panel.
Parsing and Extracting Data from HTML
Next, we need to process the raw HTML to extract meaningful data. This involves parsing the HTML content and identifying the specific information you want. To do this, first analyze the HTML structure of the webpage by opening the browser’s developer tools (press Ctrl + I or F12) and inspecting the elements to locate where the data is and in which HTML elements it resides.
Analyzing HTML Structure
Begin by analyzing the HTML structure of the webpage. Open your browser’s developer tools (press Ctrl + Shift + c ) and examine the elements to locate where the data resides and which HTML elements contain it. For example, on a page with a list of countries, each with its capital, population, and area, click on one of those countires elements to navigate to its HTML in the developer tools. Identify the selector that can be used to select those elements. On this webpage, the information about countries is contained within an element with the .countries class. You can use this class to extract all the data for the countries.
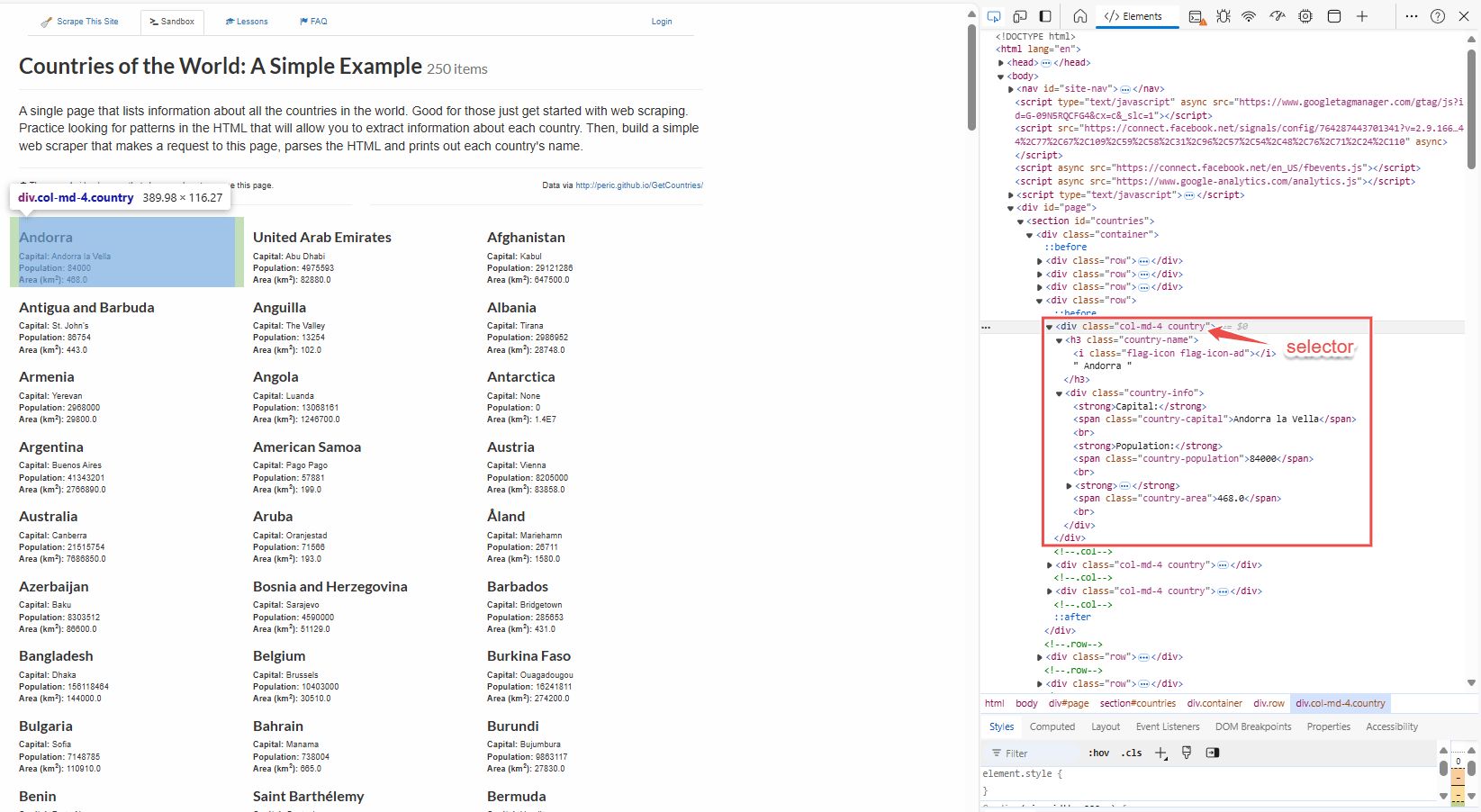
Using Node-RED to extract data
- Drag the html node onto the canvas.
- Double-click the html node and enter the selector
.countriesinto the "Selector" field. - Set the output to "only the text of element" and keep other settings default.
- Drag the debug node onto the canvas.
- Connect the output of the http request node to the input of the html node and the output of the html node to the input of the debug node.
- Click Deploy to save and deploy your flow.
When you click the inject button, you will see the array containing the text content from each .countries div. While this data is a good starting point, it has yet to be in a format that is directly useful for analysis. To make the data more helpful, you'll need to transform it into objects with meaningful properties.
Transforming Data into Structured Objects
You can use JavaScript in a Node-RED function node to transform data into structured objects. If you are familiar with JavaScript, this process will be straightforward. However, if you are not, you can use FlowFuse Expert to generate the necessary function. For more details, refer to our LinkedIn Post for a quick guide. However, in this section, we will use a low-code approach to transform the data.
-
Drag a Split node onto the canvas and connect it to the HTML node. This Split node will split the input array into individual string messages.
-
Drag a Change node onto the canvas and connect it to the Split node. Set
msg.nameto the following JSONata expression to extract the country name:$trim($split(payload, "Capital: ")[0]) -
Set
msg.payloadto the following Jsonata expression that will extract the capital and population from the string:$split($split(payload, "Capital: ")[1], "Population: ") -
Drag another Change node onto the canvas and connect it to the previous Change node. Set
msg.capitalto the following Jsonata expression to trim and extract the value of the capital from the previously split data array:$trim(payload[0]) -
Set
msg.payloadto the following Jsonata expression to split the remaining string for area extraction:$split(payload[1], "Area (km2): ") -
Drag another Change node onto the canvas and connect it to the Change node from the previous step. Set
msg.populationto the following Jsonata expression to trim and convert the population value to a number:$number($trim(payload[0])) -
Set
msg.areato the following Jsonata expression to trim and convert the area value to a number:$number($trim(payload[1])) -
Drag another Change node onto the canvas and connect it to the last Change node. Set
msg.payloadto the following JSON object:{
"name": name,
"capital": capital,
"population": population,
"area": area
} -
Finally, drag a Join node onto the canvas and connect it to the previous Change node. This Join node will create an array of the objects we have created.
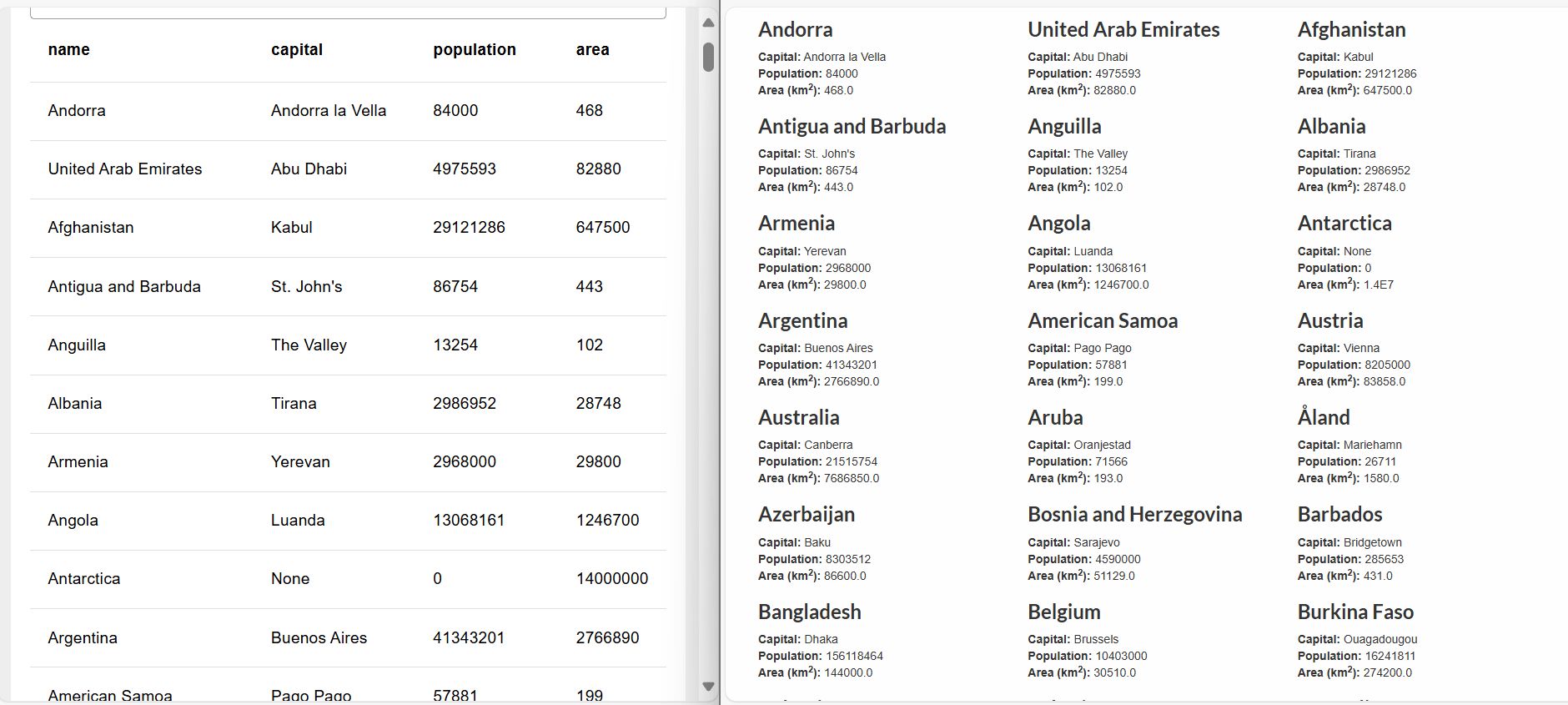
When you click the inject button again, you will see that the data is now structured and formatted. The output will contain objects with properties such as name, capital, population, and area. This data can now be displayed on the FlowFuse dashboard table. For more details, refer to the FlowFuse table widget.
Legal and Ethical Considerations
Web scraping can be a valuable tool for gathering data, but it's crucial to navigate the legal and ethical landscape responsibly. Adhere to websites' terms of service, respect intellectual property and data privacy laws, and avoid actions that could disrupt a site's operation or misuse the scraped data. By staying informed and adhering to best practices, you can harness the power of web scraping tools like Node-RED while remaining ethically and legally compliant.
Conclusion
You’ve now learned to use Node-RED for web scraping, from sending requests and parsing HTML to transforming data into practical formats. This approach streamlines data collection from websites, making it easier to manage and analyze information efficiently.
Automate Data Collection With Node-RED
FlowFuse gives you a production-ready platform to build, deploy, and manage Node-RED flows — with team collaboration, version control, and centralized management across all your instances.
About the Author
Sumit Shinde
Technical Writer
Sumit is a Technical Writer at FlowFuse who helps engineers adopt Node-RED for industrial automation projects. He has authored over 100 articles covering industrial protocols (OPC UA, MQTT, Modbus), Unified Namespace architectures, and practical manufacturing solutions. Through his writing, he makes complex industrial concepts accessible, helping teams connect legacy equipment, build real-time dashboards, and implement Industry 4.0 strategies.